Hi there, future text miners. Before we head down the coal shoot together, I’ll begin by saying this, and I hope it will reassure you- no matter your level of expertise, your experience in writing code or conducting data analysis, you can find an online tool to help you text mine.
The internet is a wild and beautiful place sometimes.
But before we go there, you may be wondering- what’s this Brave New Workplace business all about? Brave New Workplace is my monthly discussion of tech tools and skill sets which can help you adapt and know a new workplace. In our previous two installments I’ve discussed my own techniques and approaches to learning about your coworkers’ needs and common goals. Today I’m going to talk about text mining the results of your survey, but also text mining generally.
Now three months into my new position, I have found that text mining my survey results was only the first step to developing additional awareness of where I could best apply my expertise to library needs and goals. I went so far as to text mine three years of eresource Help Desk tickets and five years of meeting notes. All of it was fun, helpful, and revealing.
Text mining can assist you in information gathering in a variety of ways, but I tend to think it’s helpful to keep in mind the big three.
1. Seeing the big picture (clustering)
2. Finding answers to very specific questions (question answering)
3. Hypothesis generation (concept linkages)
For the purpose of this post, I will focus on tools for clustering your data set. As with any data project, I encourage you to categorize your inputs and vigorously review and pre-process your data. Exclude documents or texts that do not pertain to the subject of your inquiry. You want your data set to be big and deep, not big and shallow.
I will divide my tool suggestions into two categories: beginner and intermediate. For my beginners just getting started, you will not need to use any programming language, but for intermediate, you will.
Beginner

Start yourself off easy and use WordClouds.com. This simple site will make you a pretty word cloud, and also provide you with a comprehensive word frequencies list. Those frequencies are concept clusters, and you can begin to see trends and needs in your new coworkers and your workplace goals. This is a pretty cool, and VERY user friendly way to get started text mining.
WordClouds eliminates frequently used words, like articles, and gets you to the meat of your texts. You can copy paste text or upload text files. You can also scan a site URL for text, which is what I’ve elected to do as an example here, examining my library’s home page. The best output of WordClouds is not the word cloud. It’s the easily exportable list of frequently occurring words.
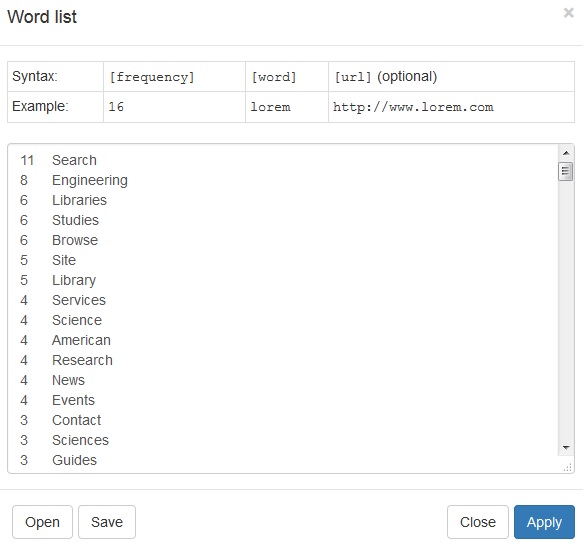
To be honest, I often use this WordClouds’ function in advance of getting into other data tools. It can be a way to better figure out categories of needs, a great first data mining step which requires almost zero effort. With your frequencies list in hand you can do some immediate (and perhaps more useful) data visualization in a simple tool of your choice, for instance Excel.
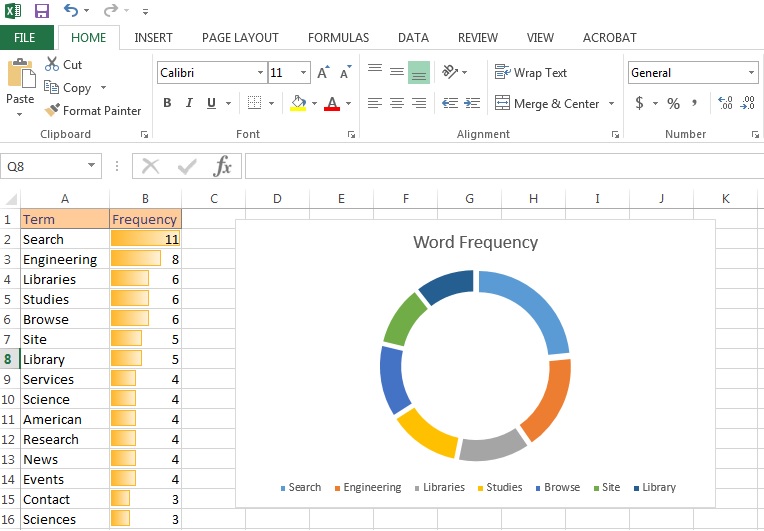
Intermediate Tools
Depending on your preferred programming language, many options are available to you. While I have traditionally worked in SPSS for data analysis, I have recently been working in R. The good news about R versus SPSS- R is free and there’s a ton of community collaboration. If you have a question (I often do) it’s easy to find an answer.
Getting started in R with text mining is simple. You’ll need to install the packages necessary if you are text mining for the first time.

Then save your text files in a folder titled: “texts,” and load those in R. Once in, you’ll need to pre-process your text to remove common words and punctuation. This guide is excellent in taking you through the steps to process your data and analyze it.
Just like our WordClouds, you can use R to discover term frequencies and visualize them. Beyond this, working in R or SPSS or Python can allow you to cluster terms further. You can find relationships between words and examine those relationships within a dendrogram or by k-means. These will allow you to see the relationships between clusters of terms.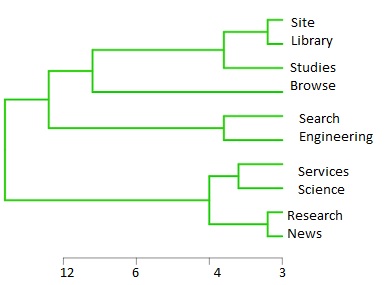
Ultimately, the more you text mine, the more familiar you will become with the tools and analysis valuable in approaching a specific text dataset. Get out there and text mine, kids. It’s a great way to acculturate to a new workplace or just learn more about what’s happening in your library.
Now that we’ve text mined the results of our survey, it’s time to move onto building a Customer Relationship Management system (CRM) for keeping our collaborators and projects straight. Come back for Brave New Workplace: Your Homegrown CRM on January 11th.
Pingback: Brave New Workplace: Your Homegrown CRM – LITA Blog