
Courtesy of Alex Berger under a CC BY-NC 2.0 license
Introduction
This is part two of my Linked Data Series. You can find the first post here. Linked Data is still a very abstract concept to many. My goal in this series is to demystify the notion. To that end I thought “wouldn’t it be cool to put Linked Data to practice, to build a proof-of-concept record”, so I did. I decided to create a Linked Data catalog record, because I wanted to write something relatively quickly, though I later found out that even writing a simple catalog record in Linked Data was going to be more effort than I anticipated.
About the Record
Link to display record: link
Link to visual graph of record: link
Link to code: link
First, here’s a link to the display record. It might take a second to load, as it is pulling in a bit of data. At first glance it doesn’t seem to be anything special. It just looks like a normal HTML display. However, under the hood there’s a lot of Linked Data magic going on. Almost all of the data you see on the page, including text values and links, are coming from RDF files (RDF is a framework for representing Linked Data. I’ll go into more detail on RDF in a future post). There’s actually multiple levels of Linked Data in the record. The first level of data is coming from an RDF file I wrote to represent the resource, in this case the book Moby-Dick. The second level of data, labels such as Melville, Herman, 1819-1891 and any data nested under more info, is coming from third party resources that I am linking to in my RDF file. For example, Creator and Subject labels are being pulled from the Library of Congress’ Linked Data Service.
Since all of the data is being pulled from online resources (using PHP), there is no duplication of data that we currently see in traditional catalogs. One big advantage to this is that when one of the linked-to sources updates its metadata, that metadata is automatically updated on the page I created!
In case this still seems foreign to you, I would recommend taking a look at a visual graph representation of the record. All of the little bubbles represent RDF resources that I am linking to. Clicking on one of the bubbles will expand that resource and will show other metadata about the linked-to resource. This is what Linked Data is about!
Here’s a screenshot example of the visual graph:
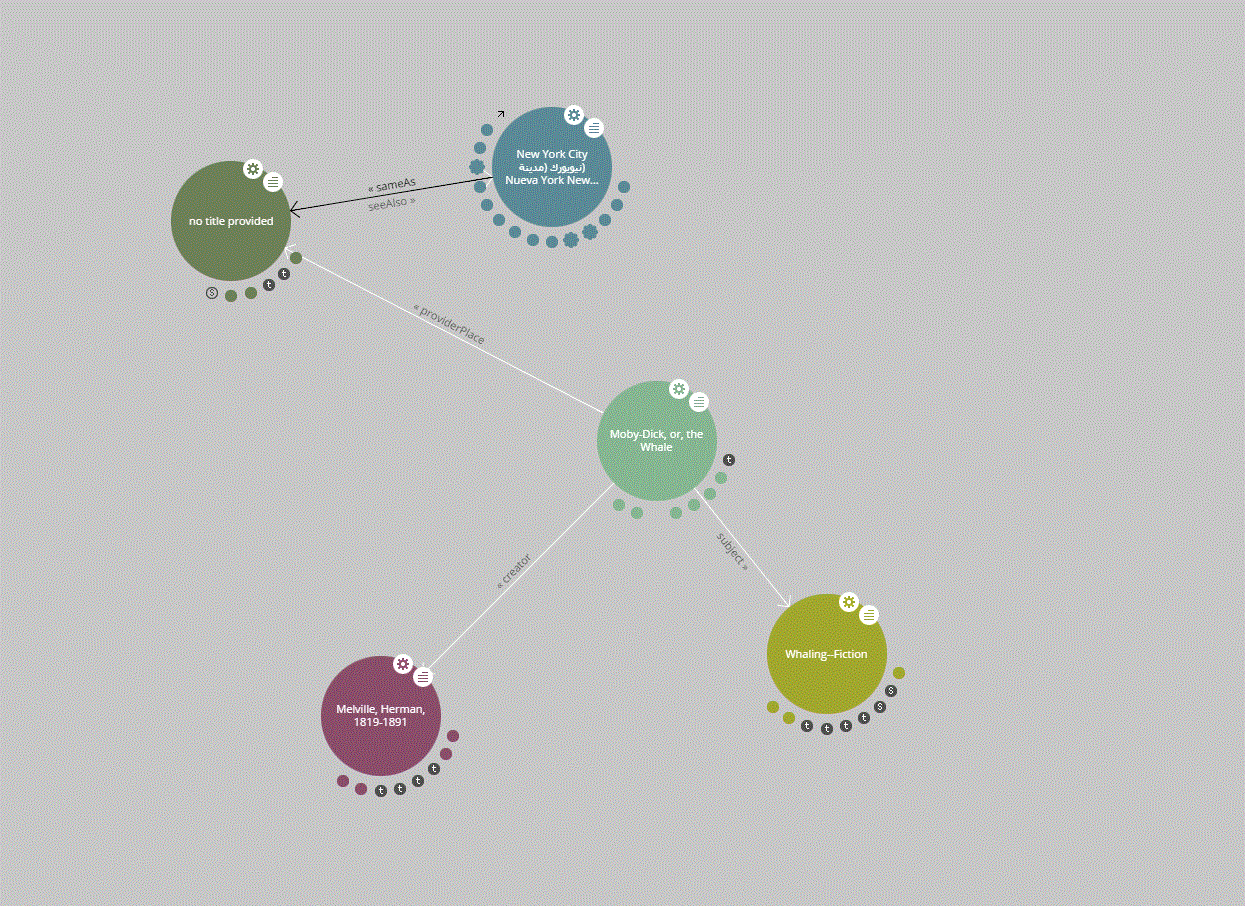
Challenges
There are a few challenges that I ran into during this adventure. First, I had to write a fair amount of PHP code to pull in the Linked Data from RDF files. I will admit that I’m a novice PHP coder, so this is most likely due to my limited knowledge of PHP and the EasyRDF PHP library that is being used. I challenge any coders out there to hack at my code and provide a cleaner solution! Here’s a link to the code (hosted on GitHub).
The second challenge is that in order to pull in third party Linked Data, I had to familiarize myself with each source’s data model (ex. Dublin Core, MADS). Almost every source’s metadata that I linked to had its own model, which reminds me of tales about the early days of library XML metadata before interoperability standards were designed. We need more interoperability in the Linked Data world! The third challenge is the main caveat of Linked Data: dependency on stable URLs. If any of the sources I link to decide to remove a URL or alter a domain without providing a URL redirection, that data is unreachable. Linked Data adds more power to metadata, but with great power… In all seriousness, stable URLs are needed in order for the Web of Data to become a reality.
All of these challenges are things developers and metadata professionals will need to face, not necessarily the catalogers, reference librarians, and archivists.
Conclusion
I hope this proof-of-concept example helped demystify Linked Data (at least to a small extent). If you have any questions or want to talk about the code, don’t hesitate to contact me! I will continue my efforts in future posts. Up next in my series will be a few interviews with librarians in various aspects of digital libraries who are working on or with Linked Data. Until next time!
Pingback: Latest Library Links 6th November 2015 | Latest Library Links
Ryan Shaw
Thanks for your post; I think it will be very helpful for people coming to grips with Linked Data. I want to respond to one point you make:
The second challenge is that in order to pull in third party Linked Data, I had to familiarize myself with each source’s data model (ex. Dublin Core, MADS). Almost every source’s metadata that I linked to had its own model…
I think it is useful to distinguish between data models and vocabularies. One of the nice things about Linked Data is that everyone is using the same data model: RDF. This makes it easy to combine data from different sources. But it is true that doing useful things with the combined data requires knowing something about, and mapping between, the various vocabularies, and familiarizing oneself with these can be a challenge. I agree that LibraryLand has more vocabularies than they need.
Jacob Shelby
Hi Ryan. Thanks for your comment! I don’t think I communicated the quoted part very clearly. There’s a mesh of terminology in this case. I agree that RDF is the common denominator and is a data model. I also agree that Dublin Core, MADS, etc are vocabularies. However, there’s a third component: formal specification/documentation/commitment to using a combination of vocabularies for describing resources using RDF. For example, you can choose to use dc:title, schema:name, and dct:versionOf when describing a resource, which isn’t completely achievable with straight-up XML. In some institutions this specification/documentation/commitment is called a data model. For instance, look at DPLA and Europeana. They have clear documentation and commitment to a specific set of combined vocabularies to use in their systems. DPLA refers to this as their metadata model; Europeana refers to it as their data model. That’s what I was referring to when I said “data model”.
Having messed with SPARQL, and in creating this Linked Data catalog record, I can say that you really do have to know a data provider’s “data model” (not the RDF data model) in order to successfully query their datasets. This can become quite compounded when you begin to query multiple data providers’ datasets, which is why I believe we, as a library community, will eventually need to commit to more standardization of “data models” in order for the Library Web of Data to work at high efficiency.