
Article Discussion
A month ago I came across an interesting article titled “Schema.org: Evolution of Structured Data on the Web”. In the article, R. V. Guha (Google), Ban Brickley (Google), and Steve MacBeth (Microsoft) talked about Schema.org, the history of Schema.org and other structured data on the Web, design decisions, extending the core Schema.org vocabulary, and related efforts to Schema.org. Much of the article revolved around the design decisions and implementation of Schema.org by “The Big Search Engines” (Google, Yahoo, Bing, etc).
Schema.org, first and foremost, is a set of vocabularies, or, a data model, just like Dublin Core and Bibframe. So, in that regard, we as information publishers can use the Schema.org vocabularies in whatever way we like. However, from what I can gather from the article, The Big Search Engines’ implementation of Schema.org has implications on how we publish our data on the Web . For instance, given this quote:
Many models such as Linked Data have globally unique URIs for every entity as a core architectural principle. Unfortunately, coordinating entity references with other sites for the tens of thousands of entities about which a site may have information is much too difficult for most sites. Instead, Schema.org insists on unique URIs for only the very small number of terms provided by Schema.org. Publishers are encouraged to add as much extra description to each entity as possible so that consumers of the data can use this description to do entity reconciliation. While this puts a substantial additional burden on applications consuming data from multiple websites, it eases the burden on webmasters significantly.
I can only assume that the Big Engines do not index all URI entities. It is expected that the publisher uses Schema.org class and property URIs, and optionally points to URLs as seen in this example, but does not use URIs for entities. Here’s a visual graph based on the previous example:
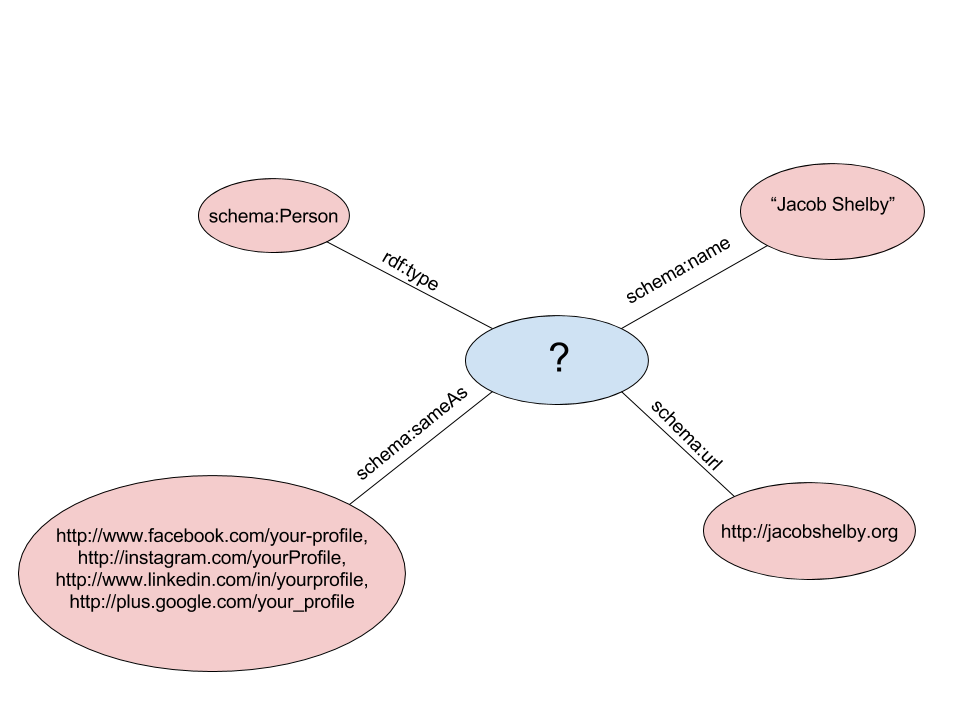
The area of concern to us Linked Data practitioners is the big question mark in the middle. Without a URI we cannot link to this entity. The lack of URIs in this example are not significant. However, when we begin to think about complex description (e.g. describing books, authors, and relationships among them), the lack of URIs makes it really hard to make connections and to produce meaningful, linked data.
Given the structured data examples by Google and the context of this article, I will also assume that the Big Engines only index Schema.org vocabularies (if anybody knows otherwise please correct me). This means that if you embed Dublin Core or Bibframe vocabularies in Web pages, they won’t be indexed.
Implications
After reading and interpreting the article, I have come up with the following thoughts that I feel will affect how we employ Linked Data:
- We will need to publish our data in two ways: as Linked Data and as Big Engine-compliant data
- No matter which vocabulary/vocabularies we use in publishing Linked Data, we will need to convert the metadata to Schema.org vocabularies when embedding data into Web pages for the Big Engines to crawl
- Before embedding our data into Web pages for the Big Engines to crawl, we will need to simplify our data by removing URIs from entities
I don’t know if that last bullet point would be necessary. That might be something that the Big Engines do as part of their crawling.
Conclusion
I want to say that none of the thoughts I mentioned above were explicitly stated in the article, they are simply my interpretations. As such, I want your input. How do you interpret the article? How do you see this affecting the future of Linked Data? As always, please feel free to add comments and questions below.
Until next time!